Seřazení hodnot na základě jiného sloupce
Stalo se vám někdy, že jste si začali tvořit graf v Power BI a sloupec, který jste vložili do pole pro osu rozházelo hodnoty pole dosti nelogicky?

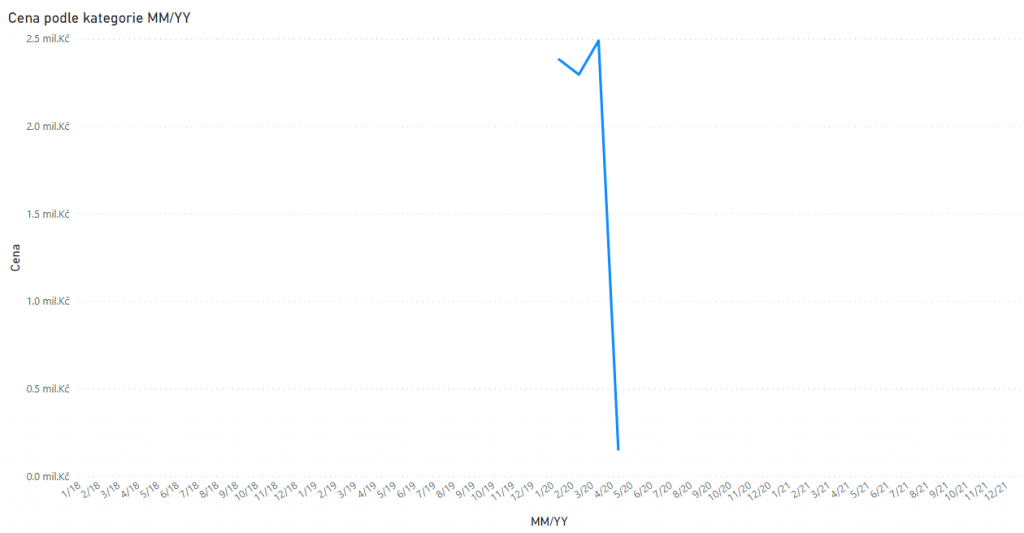
Dotaz na toto téma, jak mohu změnit seřazení osy, aby to bylo přesně jak jsem si představoval, jsem slyšel mnohokrát. Například v zobrazeném grafu máme osu tvořenou ze sloupce s hodnotou, která se skládá z měsíce a roku ve formátu MM/YY. Dokud máme jen jeden rok, tak vše půjde nastavit nativně přímo v grafu, pomocí tří teček a funkce řadit podle.

Jak Power bi řadí hodnoty na ose?
Power BI v tu chvíli identifikuje první číselné hodnoty z použitého sloupce neboli měsíce v našem případě a provede seřazení na základě nich. Jak jste si ale mohli všimnout na prvním obrázku, tak v případě, že máme více let, pak dochází k seřazení jako u klasického slovníku. Nejprve se shluknou první čísla – měsíce a následně druhá čísla – roky. Pokud bychom tak chtěli zobrazit vývojovou křivku, tak výsledek bude dosti nevalný, protože bychom viděli vývoj v jednom měsíci po letech. Nikoliv celkový vývoj v čase.
Jak tedy dosáhnu toho, že se mi osa seřadí správně?
V rámci sekce Nastavení sloupců existuje funkce, která se jmenuje Seřadit podle sloupce. Funkce se provádí na právě zvolený sloupec, tak pozor, abyste si nepřenastavili seřazení sloupce, kterého nechcete. Pokud bychom zkusili provést seřazení pomocí této funkce nad sloupcem MM/YY za pomocí sloupce Date (Datum), kdy je tento sloupec vytvořen jakožto doplněk u standardní datové tabulky s rozmezím datumů od 1.1.2015 do 31.12.2021, pak obdržíme následující upozornění, že sloupec Date nesmí obsahovat víc než jednu hodnotu pro jednu hodnotu aktuálně seřazovaného sloupce.

Jak to vyřešit?
Je zde velmi jednoduché řešení. Tím je vytvoření mapovací tabulky. Tato mapovací tabulka může přímo vycházet z datumové pomocí reference, kdy provedete seřazení pomocí sloupce rok, pak měsíc, necháte odstranit všechny sloupce krom našeho MM/YY a necháte odebrat duplicity. Při odebrání duplicit se Power Query chová tak, že ponechá první nalezený záznam a zbylé zahodí. Vznikne nám správně seřazený seznam, ke kterému připojíme indexový sloupec.
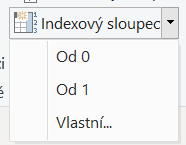
Tento indexový sloupec může začínat od nuly ale i od jedničky. Na výsledek to nebude mít vliv.

Vzhledem k faktu, že nyní máme jednu tabulku s datumy, která obsahuje duplicitní výskyty ve sloupci MM/YY, a druhou, která ne, tak můžeme provést provázání těchto tabulek v sekci Model.
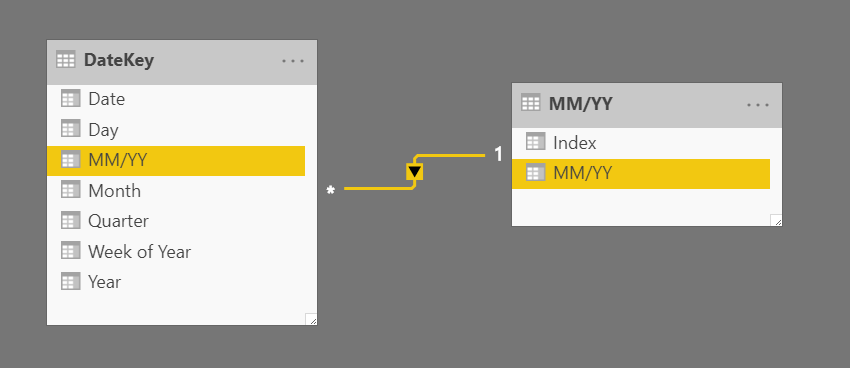
Získání výsledku
V nově vzniklé tabulce již můžeme provést funkci seřadit podle sloupce, kdy sloupec MM/YY seřadíme na základě indexu. Nelekejte se, že se na první pohled nic nezměnilo. Změna není na první pohled viditelná, ale provedla se.
Pokud se vrátím do grafu z úvodu, kam nyní umístím nově vzniklý a seřazený sloupec, tak si můžete všimnout, že dojde k získání požadovaného výsledku.
Obdobně pomocí indexu se dá provést seřazení v podstatě libovolných hodnot.